精读:Query pushdown in Cube’s semantic layer
- 原文:Query pushdown in Cube’s semantic layer
- 作者:Pavel Tiunov、Igor Lukanin
- 发布时间:2024-05-29
- 原文链接:https://cube.dev/blog/query-push-down-in-cubes-semantic-layer

这篇为什么值得读
如果你已经理解 Cube 的建模方式与 SQL API,这篇文章会进一步说明:
Cube 不是只能支持“规规矩矩”的语义查询,它正在向更复杂、更接近真实 BI 工具输出 SQL 的方向进化。
这篇文章适合说明 SQL API 的能力边界,以及官方为什么越来越重视它。
Query Pushdown 结构图
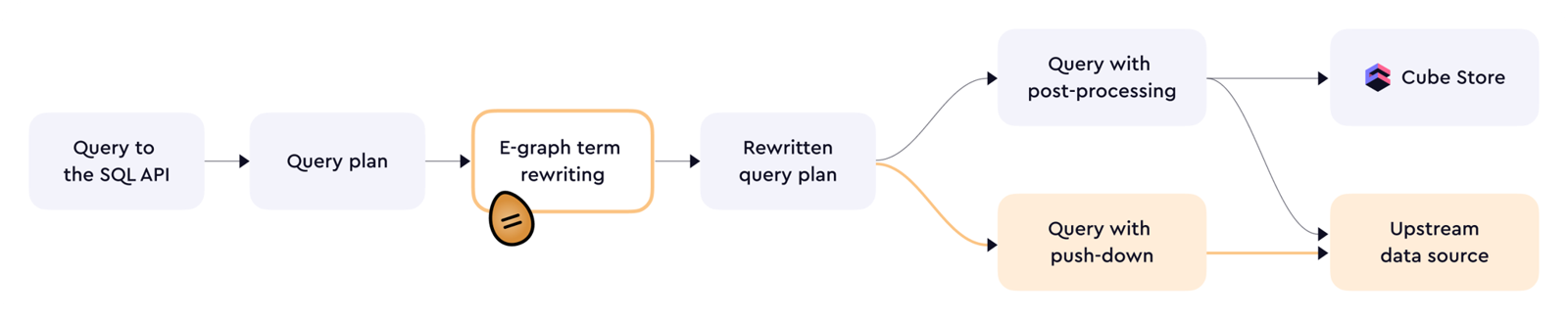
核心观点
1. SQL API 的目标是兼容越来越复杂的 BI 查询模式
原文先回顾了 SQL API 的应用范围:Power BI、Tableau、ThoughtSpot、Sigma、Superset、Metabase 等。
这意味着 SQL API 的难点不在“支持 SQL”,而在于:
- 这些工具会生成非常复杂的 SQL;
- 很多 SQL 并不是人手写的“整洁查询”;
- 语义层必须理解并吸收这些复杂度。
2. Query pushdown 为 SQL API 增加了一条新执行分支
文章解释了旧模式:
- 把 SQL 尽量拆成 regular queries;
- 再结合 DataFusion 做后处理。
这对很多场景已经够用,但遇到复杂表达式、相关子查询、窗口函数等时会失败。
新的 pushdown 模式允许 Cube:
- 接收 Postgres dialect 的 SQL;
- 选择把它转译到上游数据源方言;
- 在多种执行计划里选择更优路径。
3. 这不是“绕过语义层”,而是“在语义层内扩展灵活性”
这一点非常重要。
很多人看到 pushdown,会误以为语义层变成了 SQL 透传层。其实不是。
原文明确强调:
- query rewrite 仍然生效;
- multitenancy 仍然生效;
public: false的成员仍不能访问;- DDL 与系统 SQL 仍被忽略。
所以它增加的是 受治理前提下的表达力。
4. 它特别适合 BI 工具里的即席计算与原型探索
文中给了一个很现实的使用价值:
- 用户可以在 BI 工具里临时创建 calculated dimensions / measures;
- 不必每次都先改 Cube 数据模型。
这对自助分析十分关键,因为 BI 使用者通常会先探索,再逐步沉淀分析路径。
5. 但它也引入了新的语义与安全思考
文章特别提醒:
- 用户拿到某些 dimension 后,就可能基于它做任意聚合;
- 这相当于给了更灵活的事实表访问能力;
- 不过 row-level security 仍然适用。
此外,文中还指出 ungrouped queries 的处理方式会有 breaking change,需要升级时注意。
和本教程哪几章最相关
对中国团队的启发
1. SQL API 的价值不只在于“BI 可以连上”
更大的价值是:
- 在治理内提供更高自助度;
- 允许分析用户做临时计算;
- 让语义层和 BI 之间的边界更自然。
2. 但开放性越高,view 与权限设计越重要
如果要把 SQL API 给更广泛用户使用,就应该:
- 优先暴露 views,而不是所有底层 cubes;
- 严格控制 public 成员;
- 配好 row-level security 与 API scope。
3. 这篇文章也强化了一个趋势判断
Cube 正在从“JSON 查询语义层”越来越向“语义 SQL 平台”演进。
我的补充判断
从更宏观的角度看,这篇文章的重要战略含义在于:
Cube 试图在不牺牲治理的情况下,把语义层重新变成一个对 BI 工具非常自然的“可编程数据库接口”。
这也是为什么后来官方在 2026 年文章中更明确推荐 SQL API。
一句话总结
这篇文章说明了 SQL API 的重要升级方向:在保留语义治理、安全与缓存能力的前提下,让 Cube 能理解并承接更复杂的 BI SQL。